Articles · Page 6
Older posts from the archive.
When Recommendations Meet Language: The LLM-RecSys Convergence
Most AI stacks treat the recommendation engine and the language model as two separate systems that hand off to each other. A new class of hybrid models eliminates that seam. The implications for domain-specific AI are significant.
Trading Speed for Quality: A Practical Guide to Inference-Time Scaling
Inference-time scaling lets you tune the latency-quality tradeoff at runtime instead of at training time. When to use Best-of-N sampling, beam search, iterative refinement, or one-shot generation, with real examples from clinical AI.

Inside the Black Box: What Mechanistic Interpretability Means for Builders
Healthcare AI requires explainability. 'The model said so' is not a clinical rationale. Mechanistic interpretability is the research field trying to change that. What it offers practitioners today, where the gap is, and what to do in the meantime.
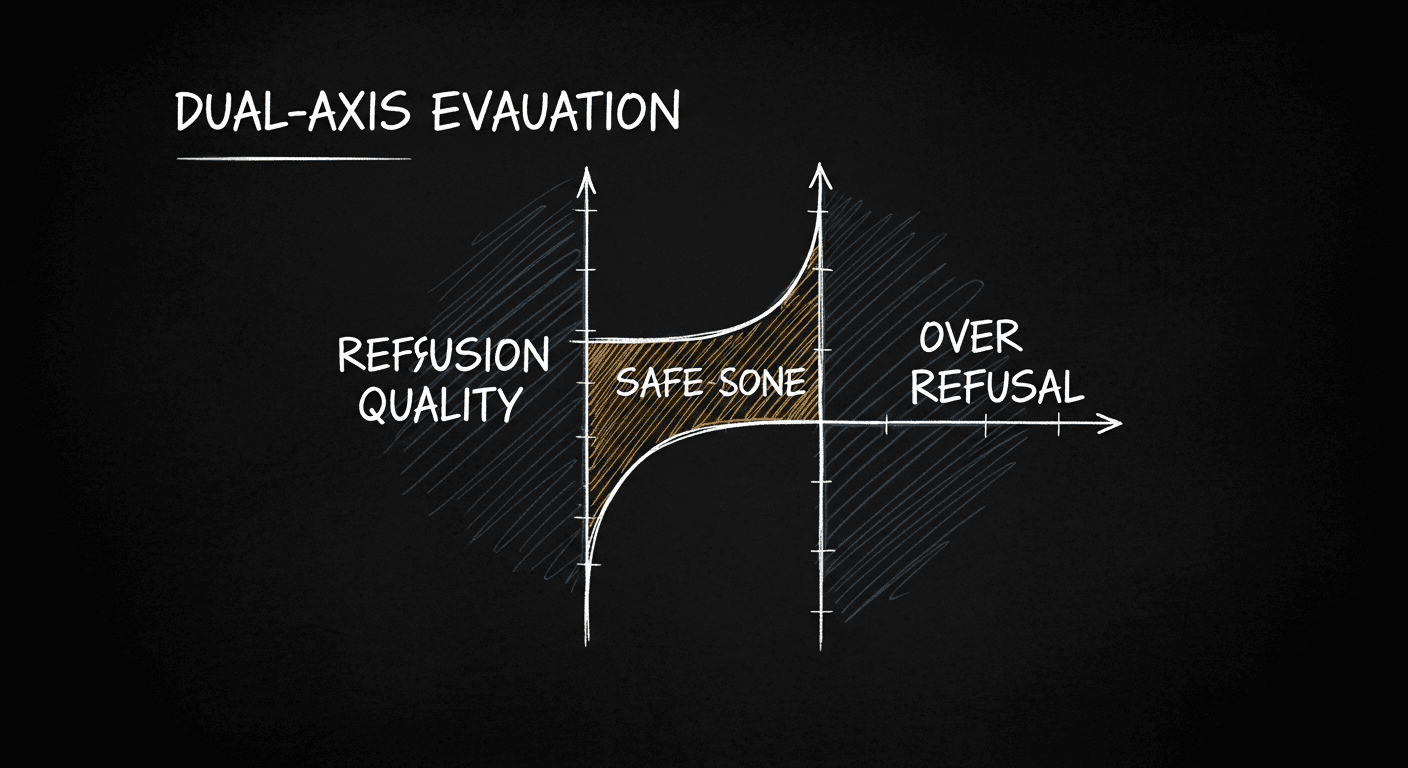
How to Actually Test If Your AI Will Say Something Dangerous
Most teams treat jailbreak testing as a vibe check. StrongREJECT achieves 0.90 Spearman correlation with human judgment. Automated safety evaluation is real, and there's no excuse not to build it into your pipeline.
The Attack Your LLM App Is Definitely Vulnerable To
Prompt injection is the #1 OWASP threat to LLM applications and most teams aren't taking it seriously. What the attack looks like, why it's hard to stop, and how to harden your system.

The Honest Guide to LLM Evals: What Actually Works
Most teams skip real evals and wonder why their AI products degrade in production. The framework that holds up: from 30-minute manual reviews to binary scoring to knowing when your eval suite is finally doing its job.

5 Reasons to Solve for Adoption Before Building Your Digital Health Tool
Clinicians love the idea but no one's buying. That gap is a pattern, and it almost never comes down to the technology. Five adoption problems to solve before you build the product.


Why Your LLM Evaluator Is Lying to You
LLM-as-judge evaluators feel like quality assurance but behave like rubber stamps. They fail hardest on the outputs that matter most: edge cases, safety-critical errors, domain-specific nuance. What to do instead.
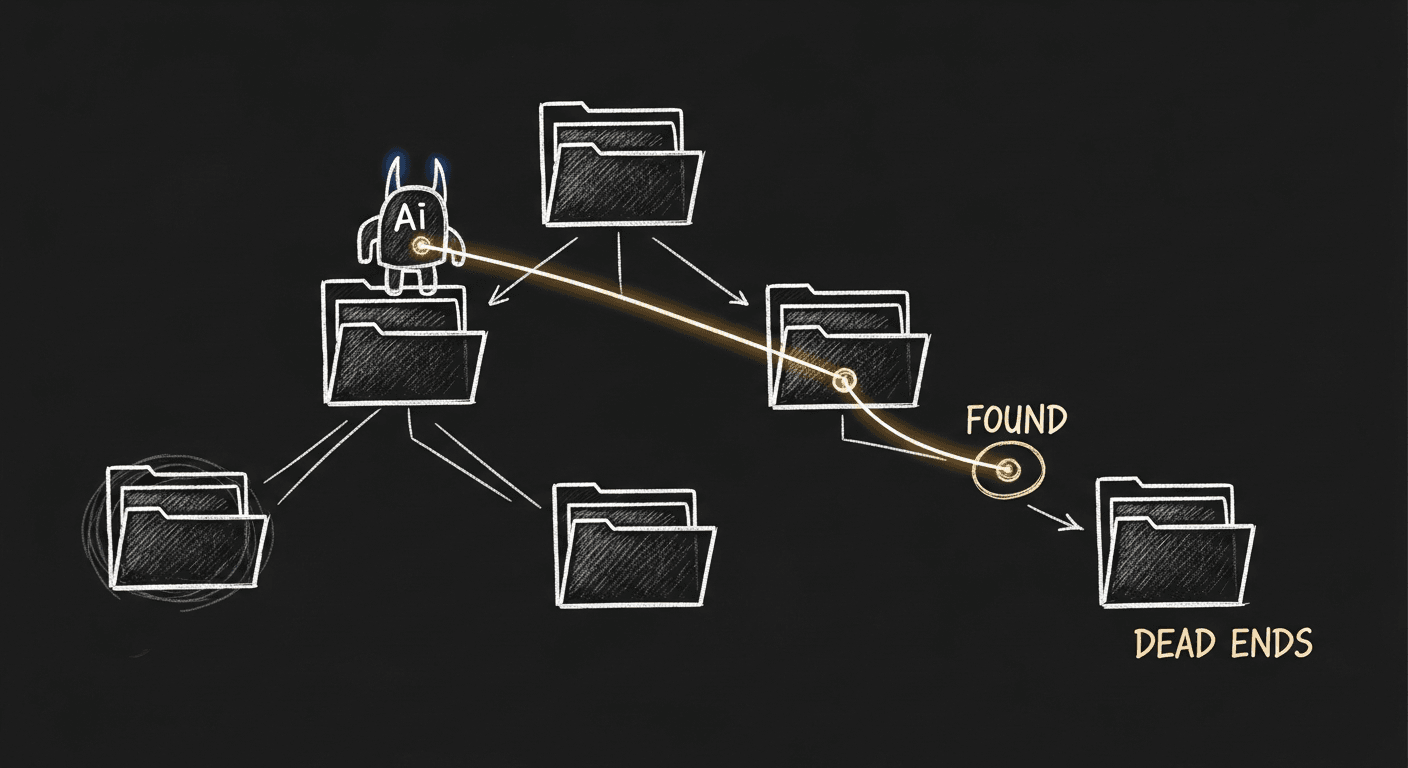
Why I Stopped Using RAG for Coding Agents (And What I Do Instead)
The instinct when building a coding agent is 'I need RAG to handle large codebases.' The better instinct is giving the agent tools to explore code the way a senior engineer would: reading files, following imports, tracing execution.